Arena Leaderboard Dataset

For almost three years, Arena has been publishing leaderboards covering frontier AI capabilities across 10 arenas, dozens of categories, and hundreds of models, and today we're releasing the entire history of those leaderboards as a public-access dataset.
We've watched how our leaderboards are cited, referenced, used, and scrutinized by academic researchers, AI labs, news outlets, and enthusiasts, and those discussions and studies have led to key insights we've acted on internally. Inspired by these interactions, and continuing in our mission of open science and community trust, we're releasing the full history of published leaderboards. We look forward to the analysis and insights the community will bring.
Overview
For ease of use, we're releasing this data as a Hugging Face dataset accessible at https://huggingface.co/datasets/lmarena-ai/leaderboard-dataset. To get started, first let's look at the data organization and schema, and then we'll look at a few examples of the types of analysis which can be performed and the insights that can be extracted from this data.
We're using the Hugging Face concepts of Splits and Subsets to segment the dataset over arenas and across time, respectively. The dataset has 14 subsets covering our 10 current arenas (four arenas have two splits for leaderboards, with and without style control). The subsets are text, vision, search, document (each with a style-controlled variant), and then webdev (code), text-to-image, image-edit, text-to-video, image-to-video, and video-edit.
Each subset has two splits, latest and full. The latest split contains only the most recently published data for the selected arena. The full split contains all historical leaderboard data for an arena.
Within a subset and split, we have a column to indicate the category, and we include the leaderboard publish date to identify exactly what each entry represents. The full schema is documented over in the readme of the dataset on Hugging Face.
Example Uses
Leaderboard Changes Over Time
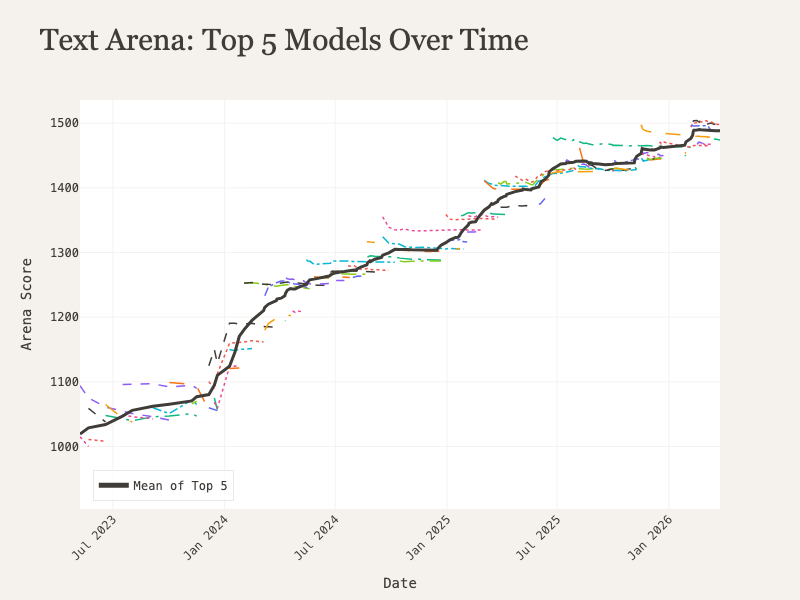
Having the full leaderboard history accessible in a single dataset unlocks some avenues of analysis beyond a static list. For example, we can look at the scores of the top five models on the Text Arena leaderboard since May 2023 and see the march of progress visually, as the mean score of the leading models has risen from a little over 1,000 to nearly 1,500.
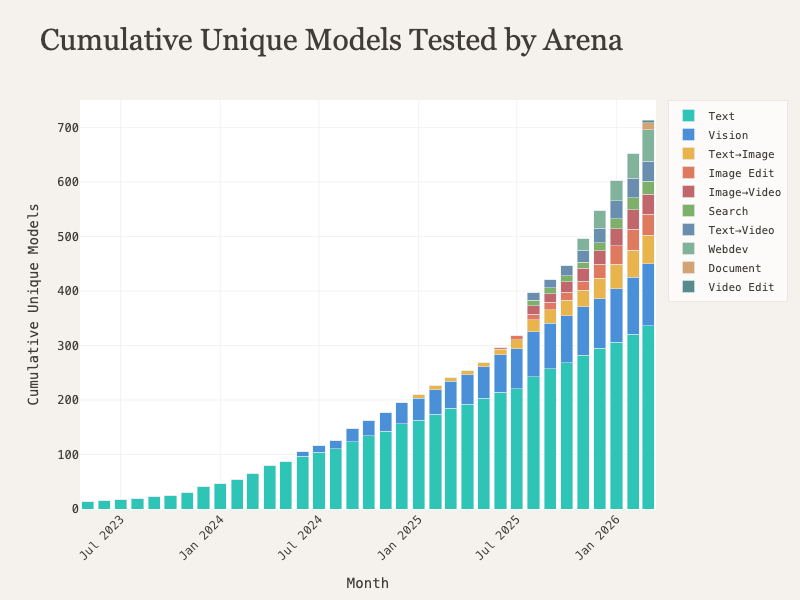
Total Models Tested
It’s also interesting to look at the total number of models we’ve tested on the platform over time. Visualizing this information really highlights the explosion of AI capabilities across different modalities and how we have scaled our evaluations to cover the field as it expands.
Proprietary vs. Open Source by Arena
This dataset also makes comparisons between arenas very straightforward. By looking at the latest split and the license column, we can get the count and rate of open source vs. proprietary models on each leaderboard. We can see that on the Text Arena leaderboard, more than half of the models are under some form of open or non-proprietary license, but that fraction is lower for other modalities and domains where the open-source fine tuning infra isn’t as mature.

Looking Ahead
We’re excited to see all the creative ways the community will use this data, and we’re excited for the next insights which will be extracted. Please feel free to reach out and ask questions in our Discord or start conversations in the community tab on Hugging Face.