Image Arena Improvements: New Categories & Quality Filtering
After analyzing over 4 million user prompts, it is clear that a single global leaderboard no longer captures the full picture. Today we introduce new categories and quality filtering.
Text-to-image models have advanced rapidly, leading to a surge in the diversity of their applications. After analyzing over 4 million user prompts—ranging from fantasy art to practical uses like logo and poster design—it is clear that a single global leaderboard no longer captures the full picture. Instead, category-specific rankings provide a clearer understanding of how different models perform across specific domains.
Furthermore, not all prompts are created equal when it comes to evaluation. Underspecified or malformed prompts introduce noise that can distort model rankings. To address these challenges, we are introducing two complementary updates to the Text-to-Image Arena:
- Prompt Categories: Enabling category-specific leaderboards for more granular performance tracking.
- Quality Filtering: Reducing noise to ensure higher ranking quality and statistical reliability.
Together, these enhancements provide a more interpretable and dependable framework for evaluating the state of the art in text-to-image generation.
Categories in Text-to-Image Arena
Categories are the primary way we organize prompts on Arena. Each text-to-image prompt can be tagged with one or more categories, though tagging remains optional. This flexibility ensures that we capture the richness of real-world use cases without forcing every conversation into a rigid box.
When you view a category leaderboard, you are seeing the same evaluation methodology as the main Text-to-Image Arena leaderboard, just filtered for that specific prompt domain. This makes categories a powerful tool for comparing model performance on specialized tasks, such as 3D generation, portraits, or commercial logo designs.
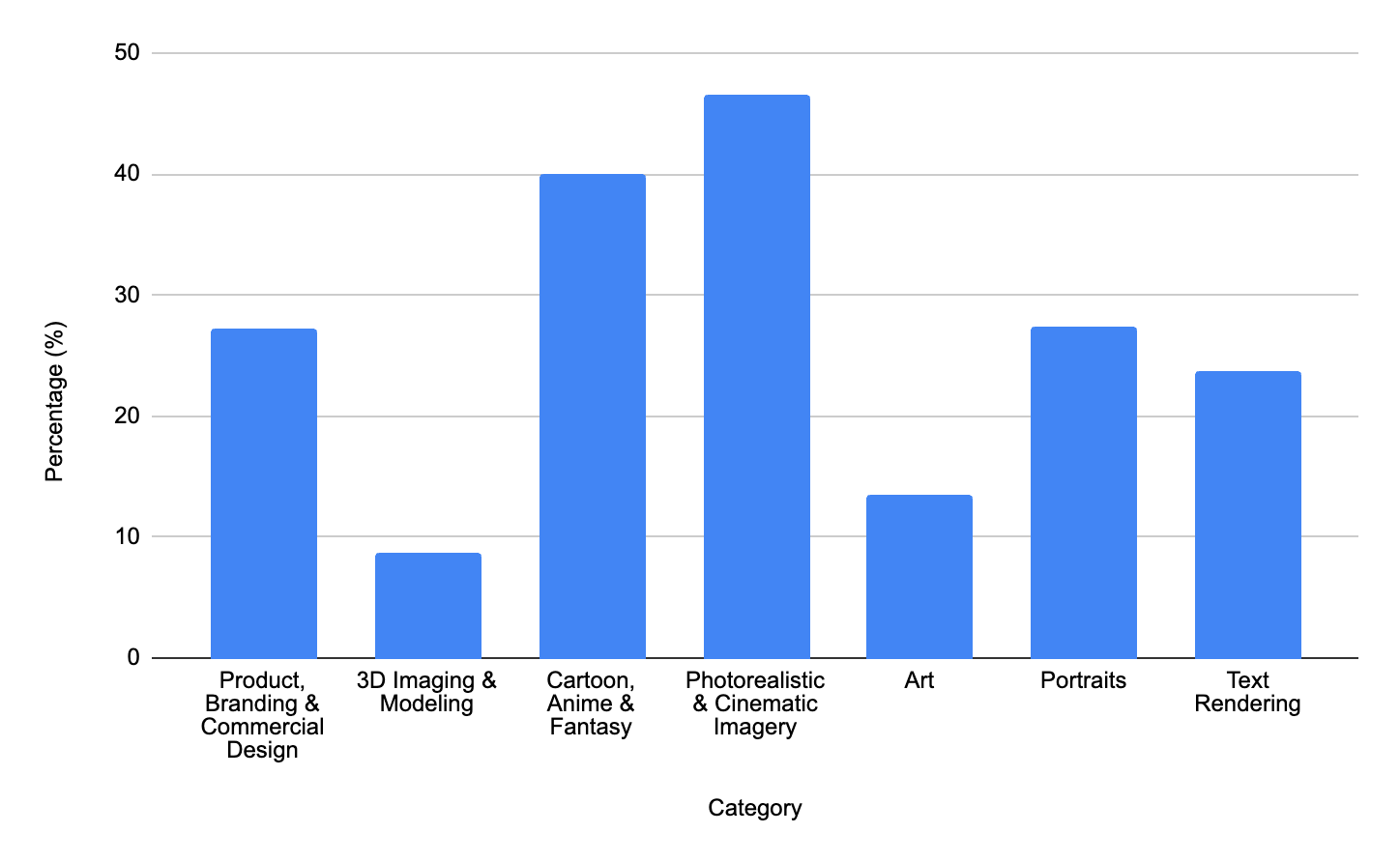
After conducting an extensive clustering analysis on a massive collection of image generation prompts, we are introducing seven distinct categories to the Text-to-Image Arena. While these categories capture a wide range of intent, their frequencies vary substantially: Photorealistic & Cinematic Imagery is the most common at roughly 43%, while specialized tasks like 3D Imaging & Modeling account for about 10%. Because these categories are not mutually exclusive, prompts can often overlap—for instance, a Product, Branding & Commercial Design prompt may frequently require high-quality Text Rendering. The figure below illustrates the distribution of these domains.
Product, Branding & Commercial Design
This category includes prompts focused on professional visual identity and marketing. It includes everything from core branding (logos and typography) and commercial photography (product ads and campaigns) to tangible assets like packaging, labels, and merchandise. It also covers digital commercial design, such as UI/UX layouts for websites and mobile applications intended for business use.
Create a square album cover for a bittersweet indie ballad about unspoken, selfless love across seasons. A poetic split scene between spring and winter: on the left, a warm spring meadow with peach blossoms and golden light; in the foreground, an East Asian young woman stands slightly turned away, hands gently clasped near her chest, eyes lowered, a tender, restrained expression as she hides her feelings. On the right, a cool winter realm in pale blue tones with soft snowfall and shimmering ice; in the middle distance, an East Asian young man smiles softly beside an East Asian young woman in a white winter coat, slightly out of focus, seen from afar, suggesting they belong together. Cherry petals and snowflakes drift toward the center and meet along a delicate seam of light that rises into the sky like a quiet prayer. Dreamy, ethereal lighting, pastel color palette, soft focus, shallow depth of field, delicate bokeh, subtle watercolor texture and film grain. Minimalist, clean composition, generous negative space, contemporary album-cover aesthetic. All characters are East Asian. No text, no logo, no watermark. High detail, high resolution, 1:1 aspect ratio. photorealistic, cinematic look, 85mm lens, wide aperture, golden-hour meets blue-hour lighting, gentle haze and rim light, natural skin tones
3D Imaging & Modeling
This category identifies prompts centered on 3D construction, digital rendering, and asset creation. It focuses on the geometry and physical presence of subjects, covering everything from sculpted characters and environmental dioramas to collectible figurines like resin statues and scale models. It also captures specific digital aesthetics—including pixel-style assets, low-poly, voxel, and isometric views—along with functional 3D icons.
A Pixar-style 3D digital illustration of a young working woman, around 30 years old, joyfully preparing and actively eating a simple, quick meal in her cozy home kitchen. She is wearing a light pink sweatshirt and grey pajama pants, looking fresh and genuinely happy. She holds a spoon with a visible bite of chapati with sabzi lifted toward her mouth, mid-action, clearly showing that she is about to eat. In her other hand, she holds the bowl comfortably. Her facial expression is cheerful and content, enjoying the simplicity of the meal. The kitchen is cozy and minimal, with soft lighting and fresh ingredients like oats, lettuce, or tomatoes visible on the counter to emphasize the healthy, easy meal. Camera angle: wide side shot, capturing her full body and the surrounding kitchen space. Emphasize the eating action: spoon visibly lifted with food, her mouth slightly open as she’s about to take a bite. Pixar-style detailing with soft textures, rounded family-friendly features, and bright, welcoming colors. Frame ratio: 9:16. The mood should strongly convey simplicity, happiness, and ease in the kitchen.
Key Focus Adjustments:
Clearly mid-action: spoon with food lifted, about to eat.
One hand holding bowl, one hand holding spoon.
Wide side shot to capture both preparation and joyful eating.
Chapati dal are more easily generated than abstract “quick meals.
Cartoon, Anime & Fantasy
This category focuses on stylized aesthetics and imaginative storytelling. It captures prompts that move away from photorealism in favor of illustrative techniques, ranging from traditional anime and manga (like Ghibli or cel-shaded styles) to Western cartoons and comic book layouts. Beyond style, it also encompasses fantastical themes, including high fantasy, mythology, and speculative genres, where the subject matter transcends everyday reality.
Create a dark fantasy cartoon illustration of Egg of Dread. The chick should be emerging from the bottom half of a cracked eggshell, with its body partially inside the shell. The chick should have wide, fearful eyes, clutching a broken lantern. Props include claw marks, shadow glyphs, and cracked bones. Symbols should include fear spirals, jagged runes, and looming eye glyphs. Background should feature looming shadows, faint mist, and broken structures. Use a color palette of black, muted gray, pale blue, and crimson. Add textures like cracked shell with shadow glyphs, mist overlay, and claw mark etching. Use a bold, clean dark fantasy cartoon style with smooth outlines and rich, flat colors. Keep the background clean and uncluttered. Minimize excess texture or random marks. Symbols should be crisp, evenly spaced, and clearly legible. Avoid sketch-like noise or heavy crosshatching.
Photorealistic & Cinematic Imagery
This category includes prompts focused on realistic photography or film/TV aesthetics, with attention to lenses, lighting, grading, and naturalistic detail and photography aesthetic style.
Generate a hyper-realistic, award-winning photography-style image of a misty autumn morning in a rural Danish village. The scene centers on a weathered cobblestone street glistening with dew, flanked by centuries-old half-timbered houses with sagging, ochre-painted facades and slate roofs streaked with lichen. A vintage bicycle with chipped blue paint leans against a rusty iron lamppost, its basket overflowing with fresh rye bread and wildflowers. In the foreground, a black cat with perfectly detailed fur—individual whiskers, textured paw pads, and faint mud splatters—pauses mid-stride, its eyes reflecting the soft golden light from a fog-diffused sunrise. Through the mist, distant barley fields merge with a pewter-gray sky, where a flock of starlings swirls in organic, asymmetrical patterns. Capture subtle imperfections: a cracked windowpane reflecting distorted clouds, rain-warped wooden shutters, and a frayed woolen scarf draped over a fence. Use natural lighting with nuanced dynamic range—deep shadows in alleyways, muted highlights on wet cobblestones, and a faint lens flare from the rising sun. Style: Mimic a Nikon D850 DSLR shot at 1/250s, f/2.8, ISO 200, with a 50mm prime lens. Prioritize forensic detail: fabric threads in the scarf, grain in the wooden beams, and atmospheric haze gradie
Art
This category captures prompts rooted in art history, traditional techniques, and non-commercial creative expression. It focuses on the "how" and "why" of an image, prioritizing specific art movements and the unique textures of physical or digital mediums. Rather than focusing on a literal subject, this category highlights the stylistic fingerprints of human (or AI-simulated) artistry, from the bold strokes of Impressionism to the intricate details of a stained-glass mosaic.
A highly detailed, surreal digital artwork of a humanoid face made entirely of liquid chrome and molten gold. The surface is glossy and reflective, with intricate flowing patterns and droplets suspended in mid-air. Warm orange and yellow glows emanate from within the metallic liquid, illuminating the smooth contours of the face. The eyes are closed in serene contemplation, and the background fades into deep shadow, emphasising the ethereal, otherworldly quality of the liquid metal figure. Ultra-realistic rendering, cinematic lighting, high dynamic range, 8K resolution.
Portraits
This category focuses specifically on human or character portraits, where facial structure, expression, pose, and identity are central to the prompt.
A stylish young woman poses confidently outdoors under a clear blue sky. She is wearing oversized pink-tinted sunglasses that reflect the sky, and a floral blouse with large, colorful flowers in shades of pink, green, and white. Her dark hair is tied back in a casual updo, with loose strands framing her face. She lifts one arm over her head and gently touches her neck with the other hand, striking a relaxed and elegant pose. The warm golden sunlight highlights her natural makeup and smooth skin, creating a summery, fashionable vibe.
Text Rendering
Text rendering prompts explicitly test a model’s ability to generate readable, accurate text within images, often combined with layout or design constraints.
A digital illustration with a soft pastel background featuring a Spanish inspirational quote. The top left corner contains white and pink floral decorations with green leaves. The main illustration shows a cartoon character with platinum blonde bob haircut with pink streaks hair wearing a blue and white striped shirt, standing on a wooden crate and reaching up to touch a red flower. The character is drawn in a simple, cute style with large eyes and a small nose. Below the character is a white potted plant with green leaves. At the bottom of the image is a red heart symbol. The Spanish text in the center reads "Que este día te regale paz en el alma y motivos para sonreír." The text is in black and is handwritten-style. The overall color palette consists of soft blues, pinks, whites, and greens, creating a gentle, peaceful atmosphere. The wooden crate is brown and is positioned on the right side of the character.
Illustration of Category Leaderboards
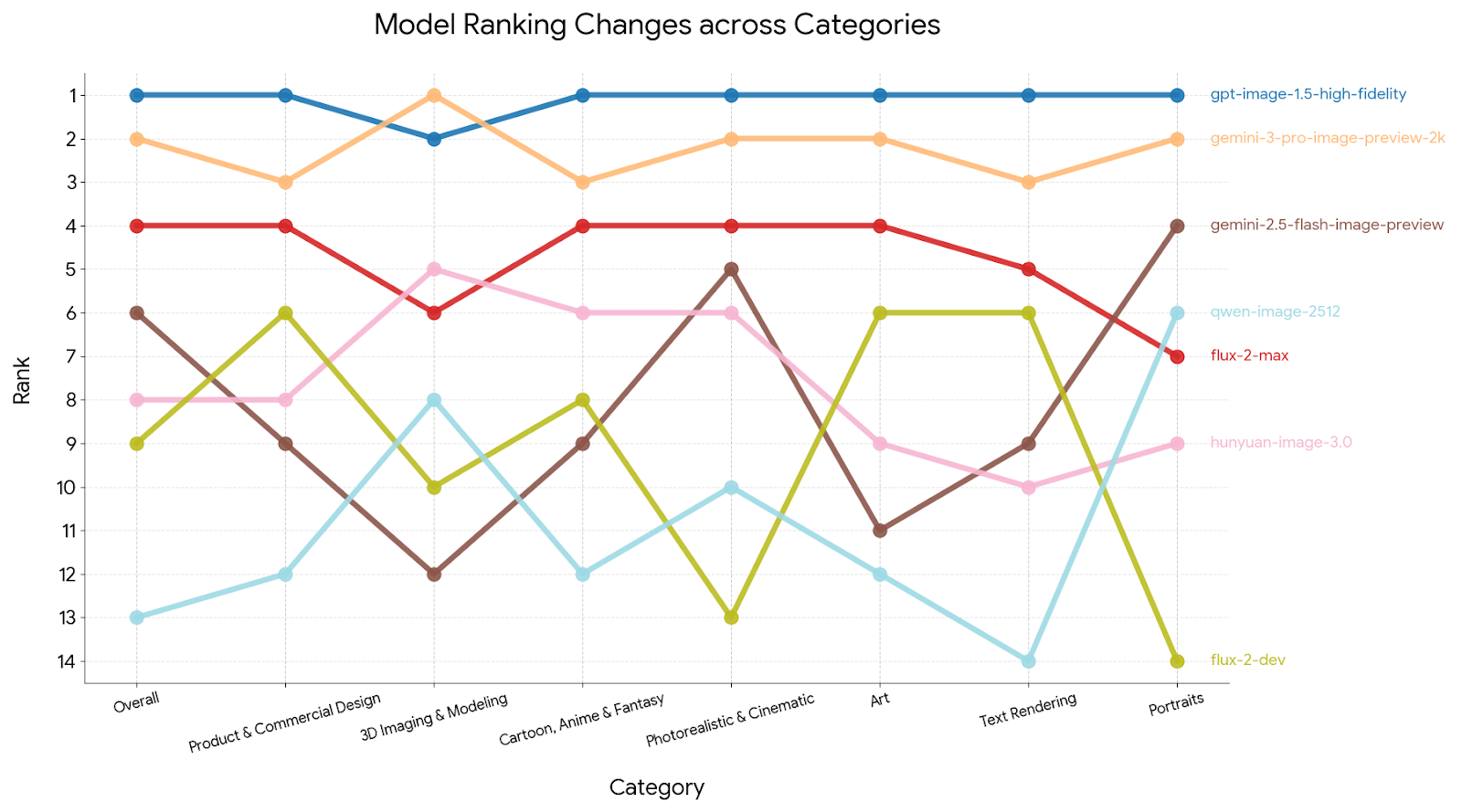
The category leaderboard provides a valuable framework for measuring a model’s specific strengths and weaknesses across different domains. To illustrate this, we selected seven representative models and visualized their overall and category rankings based on the January 28, 2026, leaderboard data. Interestingly, the category leaderboard reveals that every model possesses a unique performance profile; for instance, while GPT-image-1.5 generally maintains the top overall rank, Nano-banana-pro demonstrates superior performance in 3D Imaging & Modeling. Similarly, Qwen-image-2512 ranked #13 overall but achieves 6th place in the Portraits category. Flux-2-dev excels in Product, Branding & Commercial Design, Art, and Text Rendering, yet it underperforms compared to its peers when it comes to Portraits. For a more comprehensive look at how these and other models compare across all available metrics, we invite you to explore our full category leaderboard.
Quality Filtering
During analysis of Text-to-Image Arena prompts, we found that a subset of prompts are low quality and do not reliably elicit meaningful image generation. Many of these arise from unintended usage of the Arena—for example, users attempting image editing without uploading an image, or prompts that rely on other modalities but are submitted to the text-to-image setting. In other cases, prompts lack a concrete image generation instruction altogether, making comparisons ambiguous.
To address this, we designed an LLM-based prompt filter to identify and remove such noisy cases. After filtering out approximately 15% of prompts, we recomputed the leaderboard using the cleaned set of votes, resulting in more stable and reliable rankings.
Here are some examples of the noisy prompts:
Case 1: Resume Creation
Generate a 1-page professional resume in text format only (not in Word file),
designed to fit perfectly on one Microsoft Word page when pasted.
...
✅ Goal: Deliver the complete text-based resume output — ready to paste directly
into Word — that perfectly fits on one page, looks professionally formatted, and
passes ATS scans with a 98%+ score.
Case 2: Video Generation
Slow zoom in from a medium shot to a close-up of a woman sleeping peacefully on a
couch at a lively party. Friends tiptoe around her, placing colorful party
streamers and confetti gently on her head and shoulders. The camera then pans to
show a person carefully balancing a party hat on her head, as others in the
background try to stifle their laughter. Soft, warm lighting from string lights
casts a playful glow, creating a fun and mischievous atmosphere with a cinematic,
candid style.graphic designs. Thick black lines gradually cover her eyes, nose,
and neck as scribbled words and patterns extend down her chest, arms, and legs.
She lies unconscious on a messy bed surrounded by party chaos while the camera
circles her body, revealing the grotesque artwork covering her skin in glossy
black ink. Dim lighting reveals laughing friends in the background, empty
bottles, and scattered sharpies, with shallow depth of field focusing on the
glossy ink against her skin as she shifts slightly in her sleep. Gritty texture
enhanced by dark humor atmosphere with unsettling mood and crude graphic style
Case 3: Random Text
Random sfw
Case 4: Literature
“It’s just a small swing,” they said.
“It’s pegged to USD,” they said.
Next thing I know, I’m watching my “stable” coin do parkour.
What’s your worst FX or stablecoin horror story?
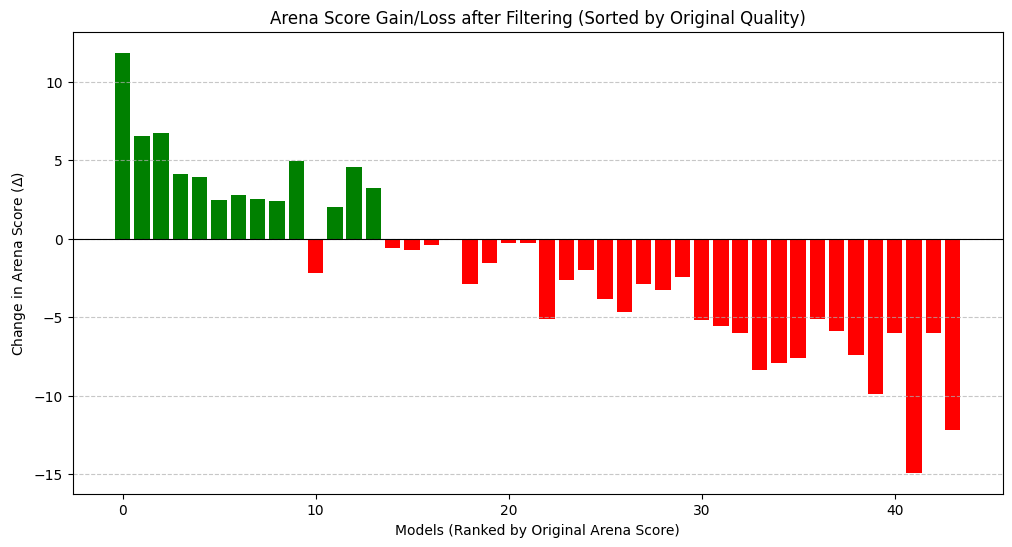
After applying our noisy prompt filter, the model leaderboard exhibits clear polarization: higher-performing models experience a relative increase in Arena Score, while lower-tier models decline further. This effect arises because noisy prompts and their associated votes tend to neutralize meaningful comparisons, suppressing the rankings of high-quality models while artificially inflating the apparent performance of weaker ones. The resulting Arena Score gains and losses across models with different original rankings are visualized below.
Looking Ahead
These categories are a first step toward more granular, interpretable evaluation of text-to-image models. As the ecosystem evolves, we expect categories to expand, shift, and refine—guided by how people actually use these models.
You can now explore how your favorite text-to-image models perform across these categories on the Text-to-Image Arena Leaderboard and help shape future evaluations by contributing prompts and votes.