Supporting Independent Research in AI Evaluation Arena’s Academic Partnerships Program provides funding and support for independent research advancing the scientific foundations of AI evaluation.
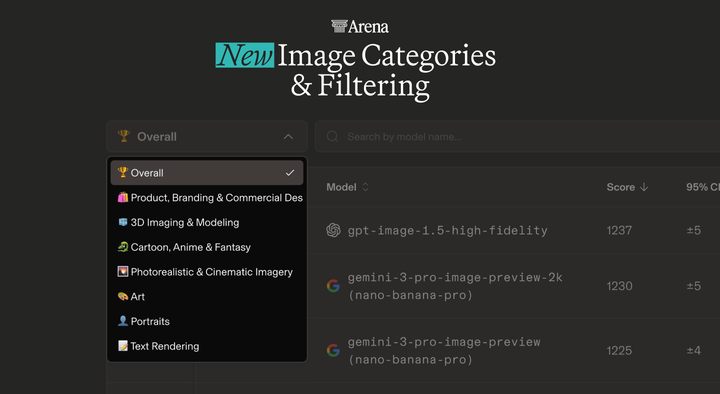
Image Arena Improvements: New Categories & Quality Filtering After analyzing over 4 million user prompts, it is clear that a single global leaderboard no longer captures the full picture. Today we introduce new categories and quality filtering.
Introducing Max Today we are releasing Max, Arena's model router powered by our community’s 5+ million real-world votes. Max acts as an intelligent orchestrator—it routes each user prompt to the most capable model for that specific prompt.
LMArena is now Arena What began as a PhD research experiment to compare AI language models has grown over time into something broader, shaped by the people who use it.
Video Arena Is Live on Web Video Arena is now available at: lmarena.ai/video! What started last summer as a small Discord bot experiment has grown into something much more substantial. It quickly became clear that this wasn’t just a novelty for generating fun videos—it was a rigorous way to measure and understand
Fueling the World’s Most Trusted AI Evaluation Platform We’re excited to share a major milestone in LMArena’s journey. We’ve raised $150M of Series A funding led by Felicis and UC Investments (University of California), with participation from Andreessen Horowitz, The House Fund, LDVP, Kleiner Perkins, Lightspeed Venture Partners and Laude Ventures.
Arena-Rank: Open Sourcing the Leaderboard Methodology Building community trust with open science is critical for the development of AI and its alignment with the needs and preferences of all users. With that in focus, we’re delighted to publish Arena-Rank, an open-source Python package for ranking that powers the LMArena leaderboard!