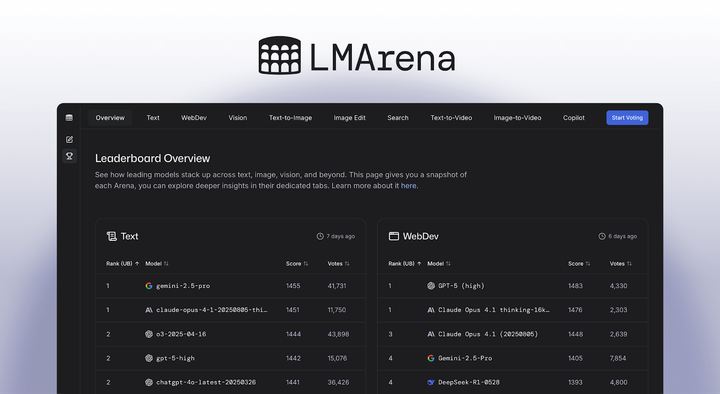
LMArena is now Arena What began as a PhD research experiment to compare AI language models has grown over time into something broader, shaped by the people who use it.
Video Arena Is Live on Web Video Arena is now available at: lmarena.ai/video! What started last summer as a small Discord bot experiment has grown into something much more substantial. It quickly became clear that this wasn’t just a novelty for generating fun videos—it was a rigorous way to measure and understand
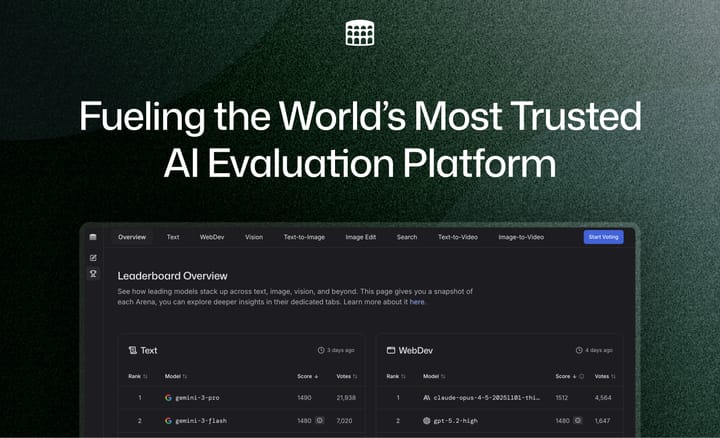
Fueling the World’s Most Trusted AI Evaluation Platform We’re excited to share a major milestone in LMArena’s journey. We’ve raised $150M of Series A funding led by Felicis and UC Investments (University of California), with participation from Andreessen Horowitz, The House Fund, LDVP, Kleiner Perkins, Lightspeed Venture Partners and Laude Ventures.
Arena-Rank: Open Sourcing the Leaderboard Methodology Building community trust with open science is critical for the development of AI and its alignment with the needs and preferences of all users. With that in focus, we’re delighted to publish Arena-Rank, an open-source Python package for ranking that powers the LMArena leaderboard!
Studying the Frontier: Arena Expert Arena Expert is a great way to differentiate between frontier models. In this analysis, we compare how models perform on 'general' vs 'expert' prompts, focusing on 'thinking' vs 'non-thinking' models.
LMArena's Ranking Method Since launching the platform, developing a rigorous and scientifically grounded evaluation methodology has been central to our mission. A key component of this effort is providing proper statistical uncertainty quantification for model scores and rankings. To that end, we have always reported confidence intervals alongside Arena scores and surfaced any
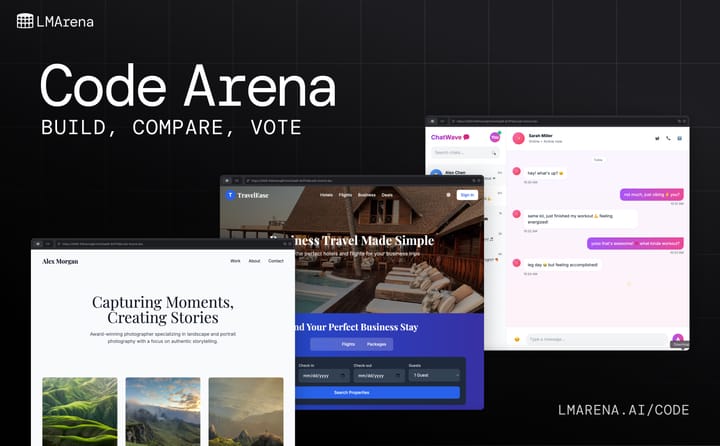
The Next Stage of AI Coding Evaluation Is Here Introducing Code Arena: live evals for agentic coding in the real world AI coding models have evolved fast. Today’s systems don’t just output static code in one shot. They build. They scaffold full web apps and sites, refactor complex systems, and debug themselves in real time. Many now
Arena Expert and Occupational Categories The next frontier of large language model (LLM) evaluation lies in understanding how models perform when challenged by expert-level problems, drawn from real work, across diverse disciplines.
Re-introducing Vision Arena Categories Since we first introduced categories over two years ago, and Vision Arena last year, the AI evaluation landscape has evolved. New categories have been added, existing ones have been updated, and the leaderboards they power are becoming more insightful with each round of community input.
New Product: AI Evaluations Today, we’re introducing a commercial product: AI Evaluations. This service offers enterprises, model labs, and developers comprehensive evaluation services grounded in real-world human feedback, showing how models actually perform in practice.
Nano Banana (Gemini 2.5 Flash Image): Try it on LMArena “Nano-Banana” is the codename that was used on LMArena during testing for what is now known as: Gemini 2.5 Flash Image. Try it for yourself directly on LMArena.ai
Introducing BiomedArena.AI: Evaluating LLMs for Biomedical Discovery LMArena is honored to partner with the team at DataTecnica to advance the expansion of BiomedArena.ai: a new domain-specific evaluation track.
A Deep Dive into Recent Arena Data Today, we're excited to release a new dataset of recent battles from LMArena! The dataset contains 140k conversations from the text arena.
Search Arena & What We’re Learning About Human Preference Search Arena on LMArena goes live today, read more about what we've learned so far about human preference with the search-augmented data.