Agent Arena: Causal Evaluation of Agents in the Real World Agents are increasingly doing real work. The resulting task distribution has greatly expanded. We desire an agent evaluation that scales along with usage and capability.
Empowering Users to Get More Done With Agent Mode The future of AI is not single-modality chat; it is in powerful agentic capabilities. Today, we are excited to introduce Agent Mode, designed to help everyone from everyday users looking to get more done to entrepreneurs looking to maximize agentic efficacy across complex use cases. While traditional chat requires
New Categories for Web Development in Code Arena AI coding models are increasingly used to build web apps, but aggregated leaderboards obscure key performance differences. After analyzing 250k+ Code Arena prompts, we identified major front-end task categories and built new leaderboard views to compare model strengths and weaknesses.
Multimodal Max Text Arena Score vs. Time to First Token Note: displayed models were the top public models when the router was created. Search Arena Score vs. Time to First Token Note: displayed models were the top public models when the router was created. Vision Arena Score vs. Time to First Token
Arena Leaderboard Dataset For almost three years, Arena has been publishing leaderboards covering frontier AI capabilities across 10 arenas, dozens of categories, and hundreds of models, and today we're releasing the entire history of those leaderboards as a public-access dataset. We've watched how our leaderboards are cited, referenced,
March 2026: Arena Updates across Product, Leaderboard Rankings & Research March 2026 brought major updates to the Arena leaderboard, including new rankings across document, video, text, and code models. In this monthly roundup, we break down the best AI models, latest LLM benchmarks, and key trends shaping AI evaluation. Whether you're a daily voter or just checking in
Inside BullshitBench: AI Models and Nonsense Detection AI failures like hallucinations are well documented. A less examined problem is that models will accept nonsensical premises without question and produce confident, detailed answers to questions that have no valid answer. BullshitBench measures whether models challenge broken premises or play along. We tested over 80 models from all major
Supporting Independent Research in AI Evaluation Arena’s Academic Partnerships Program provides funding and support for independent research advancing the scientific foundations of AI evaluation.
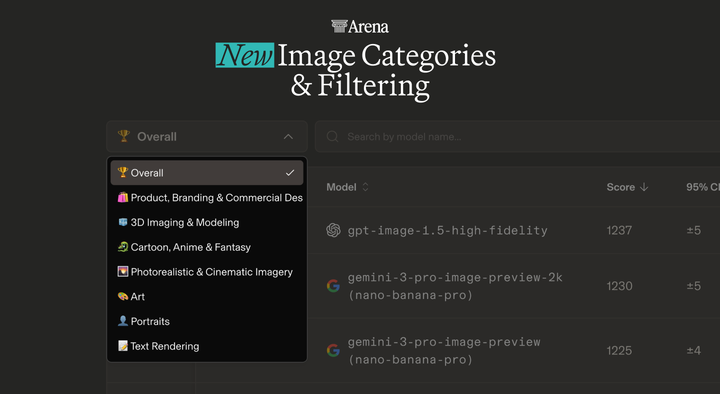
Image Arena Improvements: New Categories & Quality Filtering After analyzing over 4 million user prompts, it is clear that a single global leaderboard no longer captures the full picture. Today we introduce new categories and quality filtering.
Introducing Max Today we are releasing Max, Arena's model router powered by our community’s 5+ million real-world votes. Max acts as an intelligent orchestrator—it routes each user prompt to the most capable model for that specific prompt.
LMArena is now Arena What began as a PhD research experiment to compare AI language models has grown over time into something broader, shaped by the people who use it.
Video Arena Is Live on Web Video Arena is now available at: lmarena.ai/video! What started last summer as a small Discord bot experiment has grown into something much more substantial. It quickly became clear that this wasn’t just a novelty for generating fun videos—it was a rigorous way to measure and understand
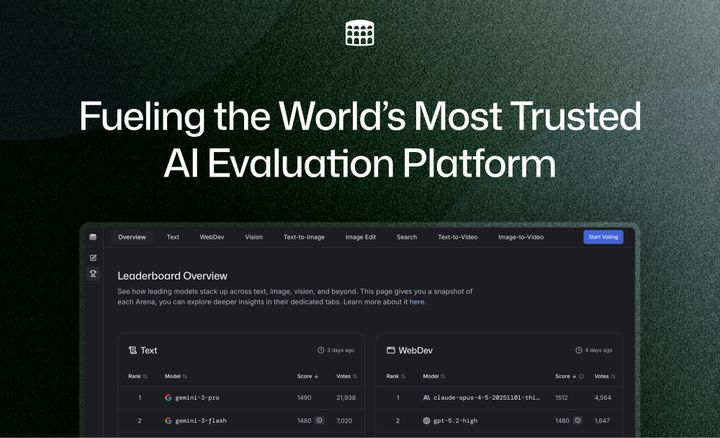
Fueling the World’s Most Trusted AI Evaluation Platform We’re excited to share a major milestone in LMArena’s journey. We’ve raised $150M of Series A funding led by Felicis and UC Investments (University of California), with participation from Andreessen Horowitz, The House Fund, LDVP, Kleiner Perkins, Lightspeed Venture Partners and Laude Ventures.
Arena-Rank: Open Sourcing the Leaderboard Methodology Building community trust with open science is critical for the development of AI and its alignment with the needs and preferences of all users. With that in focus, we’re delighted to publish Arena-Rank, an open-source Python package for ranking that powers the LMArena leaderboard!